Branching
Branch your data the same way you branch your code
With Neon, you can quickly and cost-effectively branch your data for development, testing, and various other purposes, enabling you to improve developer productivity and optimize continuous integration and delivery (CI/CD) pipelines.
What is a branch?
A branch is a copy-on-write clone of your data. You can create a branch from a current or past state. For example, you can create a branch that includes all data up to the current time or an earlier time.
A branch is isolated from its originating data, so you are free to play around with it, modify it, or delete it when it's no longer needed. Changes to a branch are independent. A branch and its parent can share the same history (within the defined point-in-time restore window) but diverge at the point of branch creation. Writes to a branch are saved as a delta.
Creating a branch does not increase load on the parent branch or affect it in any way, which means you can create a branch without impacting the performance of your production system.
Each Neon project is created with a root branch called main. The first branch that you create is branched from the project's root branch. Subsequent branches can be branched from the root branch or from a previously created branch.
Branching workflows
You can use Neon's branching feature in variety workflows.
Development
You can create a branch of your production database that developers are free to play with and modify. By default, branches are created with all of the data that existed in the parent branch, eliminating the setup time required to deploy and maintain a development database.

The following video shows how to create a branch in the Neon Console. For step-by-step instructions, see Create a branch.
You can integrate branching into your development workflows and toolchains using the Neon CLI, API, or GitHub Actions. If you use Vercel, you can use the Neon Vercel Integration to create a branch for each preview deployment.
Refer to the following guides for instructions:
Branching with the Neon API
Learn how to instantly create and manage branches with the Neon API
Branching with the Neon CLI
Learn how to instantly create and manage branches with the Neon CLI
Branching with GitHub Actions
Automate branching with Neon's GitHub Actions for branching
The Neon Vercel Integration
Connect your Vercel project and create a branch for each preview deployment
Testing
Testers can create branches for testing schema changes, validating new queries, or testing potentially destructive queries before deploying them to production. A branch is isolated from its parent branch but has all of the parent branch's data up to the point of branch creation, which eliminates the effort involved in hydrating a database. Tests can also run on separate branches in parallel, with each branch having dedicated compute resources.

Refer to the following guide for instructions.
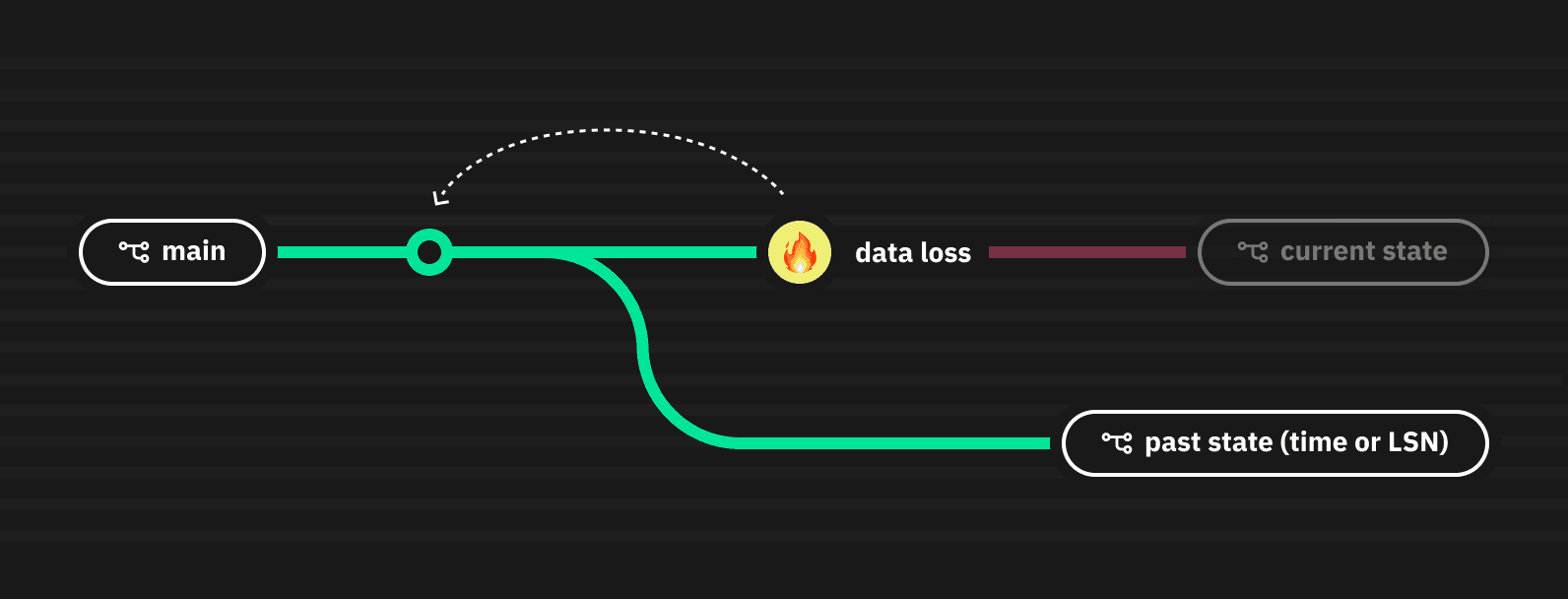
Data recovery
If you lose data due to an unintended deletion or some other event, you can restore a branch to any point in its history retention period to recover lost data. You can also create a new point-in-time branch for historical analysis or any other reason.
Refer to the following guides for instructions.
Last updated on