
Neon vs Aurora: FAQ
AWS Lambda is pretty awesome. Serverless “Functions as a Service” where you can deploy code without worrying about servers, scaling, or infra.
Well, that’s the dream. The reality can be a bit nearer earth, especially when Lambda bumps up against other services, say databases. This isn’t Lambda’s fault (Lambda really is awesome), as it is a function of how AWS services work (or don’t) together.
So, what’s the answer? Pooled connections are the way to go in this scenario, but AWS seems to be struggling even here. Let’s look into why.
When AWS Lambda and Aurora Serverless v2 Don’t Mix
At its core, the issue stems from how Lambda functions handle database connections. Each Lambda instance typically creates its own database connection, typically to Aurora Serverless v2 within the AWS ecosystem. The problem is Lambda’s autoscaling can spawn hundreds or thousands of concurrent instances within seconds. This fundamental impedance mismatch between Lambda’s scaling model and Aurora’s connection management creates a perfect storm for production incidents.
Consider this typical Node.js Lambda code:
let connection = null;
exports.handler = async (event) => {
if (!connection) {
connection = await mysql.createConnection({
host: process.env.AURORA_HOST,
user: process.env.DB_USER,
password: process.env.DB_PASSWORD,
database: process.env.DB_NAME
});
}
// Use connection...
};This code appears reasonable, and you’ve probably written something similar dozens of times. But in a serverless context, it can lead to severe issues. For example:
- Connection pool exhaustion. In Amazon Aurora Postgres, the maximum number of database connections is determined by the max_connections parameter. In Aurora Serverless v2, the default maximum connections for an instance with 1 Aurora Capacity Unit (ACU) is 90; for an instance with 64 ACUs, it is 5,000. With each Lambda instance maintaining its own connection, a sudden traffic spike can exhaust this pool within seconds. It’s also important to note that each active connection consumes memory, so manually setting a high max_connections value without enough ACUs allocated also leads to performance issues.
- Connection zombie state. When AWS Lambda functions establish database connections, each function instance typically creates its own connection. When Lambda instances go idle, their connections don’t immediately terminate. Instead, they linger in a “zombie” state, consuming resources without providing value. This is a common issue in serverless environments where functions scale rapidly.
- Cold start penalties. New Lambda instances must establish fresh database connections, adding latency (often 100-300ms) to cold starts in Aurora Serverless v2.
Is Amazon RDS Proxy the Solution? Often, It’s Not
To mitigate these issues, AWS recommends using Amazon RDS Proxy, a service that establishes a connection pool and reuses connections within this pool. The idea is to let RDS Proxy reduce the memory and CPU overhead associated with opening new database connections for each function invocation. RDS Proxy controls the number of database connections to help prevent oversubscription and manages connections that can’t be immediately served by queuing or throttling them.
But RDS Proxy has its limitations. It imposes hard limits on concurrent connections, which can lead to increased query latency and higher DatabaseConnectionsBorrowLatency metrics. RDS Proxy can also struggle with long-running transactions, as certain SQL operations can cause all subsequent statements in a session to be pinned to the same underlying database connection reducing the efficiency of connection reuse. Setting up and managing RDS Proxy is also far from straightforward, and it’s also not free.
A Real-World Example
“Neon worked out of the box, handling hundreds of Lambdas without any of the connection issues we saw in Aurora Serverless v2. On top of that, Neon costs us 1/6 of what we were paying with AWS” (Cody Jenkins, Head of Engineering at Invenco)
Invenco, an e-commerce logistics company, suffered these problems. Their architecture involved Lambda functions processing payment transactions against Aurora Serverless v2. In theory, AWS Lambda and Aurora Serverless v2 should be a match made in cloud heaven. But Aurora Serverless v2 struggled to handle the concurrent connections from their Lambda functions during traffic spikes, and adding RDS Proxy didn’t solve the issues.
Why? Let’s take a look at a typical Aurora Serverless v2 connection pattern during a traffic spike:
- t=0s: Normal traffic: 100 requests/sec, 20 active Lambda instances with 20 DB connections
- t=1s: Traffic spike begins: 2000 requests/sec hit the API Gateway
- t=1.2s: Lambda auto-scaling triggers, spinning up 200 new instances
- t=1.3s: 220 concurrent connection attempts to Aurora (20 existing + 200 new)
- t=1.4s: Aurora connection queue begins backing up
- t=1.5s: New connections start getting refused, only 100 total connections accepted
- t=1.6s: Application errors begin cascading, requests start failing
This pattern shows how a sudden 20x increase in incoming traffic creates a cascade effect. The traffic spike triggers Lambda’s autoscaling, and each new Lambda instance attempts to create its own database connection.
Aurora Serverless v2, despite being “serverless,” can’t scale its connection capacity as rapidly as Lambda scales compute, and the mismatch between Lambda’s scaling speed and Aurora’s connection capacity leads to failures.
The Solution: PgBouncer
Neon, a serverless Postgres service that can be an alternative to Aurora Serverless v2, takes a fundamentally different approach to the connection management problem by integrating PgBouncer directly into its architecture.
Rather than requiring a separate proxy service like RDS Proxy, Neon connection pooling is built into every Neon endpoint. Here’s how it works:
// Instead of connecting directly to Postgres
const db = new Client({
host: 'ep-cool-darkness-123456.us-east-2.aws.neon.tech',
...
});
// You simply add '-pooler' to your endpoint
const db = new Client({
host: 'ep-cool-darkness-123456-pooler.us-east-2.aws.neon.tech',
...
});This seemingly minor change routes your connections through PgBouncer in transaction pooling mode, which fundamentally alters how connections are managed:
- Connection scaling. While a standard Postgres instance might support only 450 connections (with 1 CPU/4GB RAM), Neon’s pooler supports up to 10,000 concurrent connections.
- Resource management. Instead of each Lambda creating a persistent connection, the pooler maintains a shared pool of 64 database connections per user/database pair. These connections are recycled efficiently across your Lambda invocations.
- Queue instead of fail: New requests are queued rather than rejected when all connections are in use. This is particularly crucial for serverless architectures where traffic can spike unexpectedly.
Remember: connection pooling isn’t magic. Those 10,000 concurrent connections still share a limited pool of actual database connections. However, for serverless architectures with many concurrent but infrequent database operations, this pattern provides the scalability needed without the operational complexity of managing your own connection pooling infrastructure.
How to Use Neon Connection Pooling With AWS Lambda
Let’s build an app that might need to take advantage of this type of pooling. We will mimic a service like Invenco with fulfillment, sales, and inventory management endpoints.
We’ll start with Neon. We’ll create a new project, our schema, and some mock data:
-- Create tables
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
sku VARCHAR(50) UNIQUE NOT NULL,
price DECIMAL(10,2) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE warehouses (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
location VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE inventory (
id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
warehouse_id INTEGER REFERENCES warehouses(id),
quantity INTEGER NOT NULL DEFAULT 0,
status VARCHAR(50) DEFAULT 'active',
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(product_id, warehouse_id)
);
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
order_id VARCHAR(50) NOT NULL,
product_id INTEGER REFERENCES products(id),
quantity INTEGER NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
status VARCHAR(50) DEFAULT 'completed',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE fulfillments (
id SERIAL PRIMARY KEY,
order_id VARCHAR(50) NOT NULL,
warehouse_id INTEGER REFERENCES warehouses(id),
status VARCHAR(50) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE fulfillment_items (
id SERIAL PRIMARY KEY,
fulfillment_id INTEGER REFERENCES fulfillments(id),
product_id INTEGER REFERENCES products(id),
quantity INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
-- Products
INSERT INTO products (name, sku, price) VALUES
('Gaming Laptop', 'TECH-001', 1299.99),
('Wireless Headphones', 'TECH-002', 199.99),
('Smartphone', 'TECH-003', 899.99),
('Tablet', 'TECH-004', 499.99),
('Smartwatch', 'TECH-005', 299.99);
-- Warehouses
INSERT INTO warehouses (name, location) VALUES
('East Coast Fulfillment Center', 'New Jersey, USA'),
('West Coast Fulfillment Center', 'California, USA'),
('Central Distribution Hub', 'Texas, USA');
-- Inventory
INSERT INTO inventory (product_id, warehouse_id, quantity) VALUES
(1, 1, 50), -- Gaming Laptops in NJ
(1, 2, 35), -- Gaming Laptops in CA
(2, 1, 100), -- Headphones in NJ
(2, 2, 85), -- Headphones in CA
(3, 1, 75), -- Smartphones in NJ
(3, 3, 60), -- Smartphones in TX
(4, 2, 90), -- Tablets in CA
(4, 3, 45), -- Tablets in TX
(5, 1, 65), -- Smartwatches in NJ
(5, 2, 55); -- Smartwatches in CA
-- Sample Sales
INSERT INTO sales (order_id, product_id, quantity, total_amount) VALUES
('ORD-2024-001', 1, 1, 1299.99),
('ORD-2024-002', 2, 2, 399.98),
('ORD-2024-003', 3, 1, 899.99),
('ORD-2024-004', 4, 3, 1499.97),
('ORD-2024-005', 5, 2, 599.98),
('ORD-2024-006', 1, 1, 1299.99),
('ORD-2024-007', 2, 1, 199.99),
('ORD-2024-008', 3, 2, 1799.98);
-- Sample Fulfillments
INSERT INTO fulfillments (order_id, warehouse_id, status) VALUES
('ORD-2024-001', 1, 'completed'),
('ORD-2024-002', 1, 'completed'),
('ORD-2024-003', 3, 'in_progress'),
('ORD-2024-004', 2, 'pending'),
('ORD-2024-005', 2, 'completed');
-- Sample Fulfillment Items
INSERT INTO fulfillment_items (fulfillment_id, product_id, quantity) VALUES
(1, 1, 1), -- Gaming Laptop for order 1
(2, 2, 2), -- Headphones for order 2
(3, 3, 1), -- Smartphone for order 3
(4, 4, 3), -- Tablets for order 4
(5, 5, 2); -- Smartwatches for order 5
-- Create indexes for better query performance
CREATE INDEX idx_inventory_product_warehouse ON inventory(product_id, warehouse_id);
CREATE INDEX idx_sales_order_id ON sales(order_id);
CREATE INDEX idx_fulfillments_order_id ON fulfillments(order_id);
CREATE INDEX idx_fulfillment_items_fulfillment ON fulfillment_items(fulfillment_id);What goes here isn’t super important; we just want to ensure we have some somewhat realistic API calls for our lambda functions. At this point, we also want to grab our database URL. Importantly, we want the “Pooled connection” option:
The only difference from a user’s point of view is the “-pooler” addition to the connection string. But as we’ll see, this makes a big difference.
With our DB string, we’ll go ahead and set up our Lambda functions (Here’s the entire AWS Lambda <> Neon setup details). First, we want to install Serverless. This framework will abstract away much of the AWS infrastructure configuration, handling everything from function deployment to API Gateway setup through declarative YAML files:
npm install -g serverlessThis will take you through the setup for a new lambda function on AWS. When complete, navigate to the new directory created by the serverless step and install the node-postgres package, which you will use to connect to the database.
npm install pgNow, we need to create our actual functions. Here are the functions we’re going to use:
// logistics.js
'use strict';
const { Client } = require('pg');
// Sales Endpoints
module.exports.getSales = async (event) => {
const client = new Client(process.env.DATABASE_URL);
await client.connect();
try {
const { rows } = await client.query(`
SELECT
s.id,
s.order_id,
s.product_id,
s.quantity,
s.total_amount,
s.created_at,
s.status
FROM sales s
ORDER BY s.created_at DESC
`);
return {
statusCode: 200,
body: JSON.stringify({
data: rows,
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Failed to fetch sales data',
}),
};
} finally {
await client.end();
}
};
// Inventory Endpoints
module.exports.getInventory = async (event) => {
const client = new Client(process.env.DATABASE_URL);
await client.connect();
try {
const { rows } = await client.query(`
SELECT
i.id,
i.product_id,
i.quantity,
i.warehouse_id,
i.last_updated,
i.status
FROM inventory i
WHERE i.quantity > 0
`);
return {
statusCode: 200,
body: JSON.stringify({
data: rows,
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Failed to fetch inventory data',
}),
};
} finally {
await client.end();
}
};
// Fulfillment Endpoints
module.exports.createFulfillment = async (event) => {
const client = new Client(process.env.DATABASE_URL);
await client.connect();
const { order_id, warehouse_id, items } = JSON.parse(event.body);
try {
// Start a transaction
await client.query('BEGIN');
// Create fulfillment record
const { rows: [fulfillment] } = await client.query(`
INSERT INTO fulfillments (order_id, warehouse_id, status, created_at)
VALUES ($1, $2, 'pending', CURRENT_TIMESTAMP)
RETURNING *
`, [order_id, warehouse_id]);
// Create fulfillment items
for (const item of items) {
await client.query(`
INSERT INTO fulfillment_items (fulfillment_id, product_id, quantity)
VALUES ($1, $2, $3)
`, [fulfillment.id, item.product_id, item.quantity]);
// Update inventory
await client.query(`
UPDATE inventory
SET quantity = quantity - $1
WHERE product_id = $2 AND warehouse_id = $3
`, [item.quantity, item.product_id, warehouse_id]);
}
await client.query('COMMIT');
return {
statusCode: 200,
body: JSON.stringify({
data: fulfillment,
}),
};
} catch (error) {
await client.query('ROLLBACK');
return {
statusCode: 500,
body: JSON.stringify({
error: 'Failed to create fulfillment',
}),
};
} finally {
await client.end();
}
};
module.exports.getFulfillmentStatus = async (event) => {
const client = new Client(process.env.DATABASE_URL);
await client.connect();
const { fulfillment_id } = event.pathParameters;
try {
const { rows } = await client.query(`
SELECT
f.*,
json_agg(
json_build_object(
'product_id', fi.product_id,
'quantity', fi.quantity
)
) as items
FROM fulfillments f
LEFT JOIN fulfillment_items fi ON f.id = fi.fulfillment_id
WHERE f.id = $1
GROUP BY f.id
`, [fulfillment_id]);
return {
statusCode: 200,
body: JSON.stringify({
data: rows[0],
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({
error: 'Failed to fetch fulfillment status',
}),
};
} finally {
await client.end();
}
};This seems a lot, but we want to show what happens when you call multiple Lambda functions with DB connections. Lastly, we need to update the serverless.yml file that will have been autogenerated to add these endpoints:
org: argot
app: neon-lambda
service: neon-lambda
provider:
name: aws
runtime: nodejs20.x
environment:
DATABASE_URL: postgresql://neondb_owner:************@ep-cold-pine-a5arwpmq.us-east-2-pooler.aws.neon.tech/neondb?sslmode=require
functions:
# Sales endpoints
getSales:
handler: logistics.getSales
events:
- httpApi:
path: /sales
method: get
# Inventory endpoints
getInventory:
handler: logistics.getInventory
events:
- httpApi:
path: /inventory
method: get
# Fulfillment endpoints
createFulfillment:
handler: logistics.createFulfillment
events:
- httpApi:
path: /fulfillment
method: post
getFulfillmentStatus:
handler: logistics.getFulfillmentStatus
events:
- httpApi:
path: /fulfillment/{fulfillment_id}
method: getNotice that this is where we’re adding our Neon connection string. This serverless.yml file acts as the infrastructure-as-code definition, declaring how our Lambda functions should be configured, what triggers them (HTTP endpoints), and what environment variables they need access to. It’s the single source of truth for our serverless architecture.
Now, all we have to do is deploy this:
serverless deployYou will get back something like this:
serverless deploy
Deploying "neon-lambda" to stage "dev" (us-east-1)
✔ Service deployed to stack neon-lambda-dev (39s)
endpoints:
GET - https://**********.execute-api.us-east-1.amazonaws.com/users
GET - https://**********.execute-api.us-east-1.amazonaws.com/sales
GET - https://**********.execute-api.us-east-1.amazonaws.com/inventory
POST - https://**********.execute-api.us-east-1.amazonaws.com/fulfillment
GET - https://**********.execute-api.us-east-1.amazonaws.com/fulfillment/{fulfillment_id}
functions:
getAllUsers: neon-lambda-dev-getAllUsers (6.1 MB)
getSales: neon-lambda-dev-getSales (6.1 MB)
getInventory: neon-lambda-dev-getInventory (6.1 MB)
createFulfillment: neon-lambda-dev-createFulfillment (6.1 MB)
getFulfillmentStatus: neon-lambda-dev-getFulfillmentStatus (6.1 MB)This means all your functions are now deployed to those endpoints, and you’re ready to go–you have serverless Lambda functions and a pooled connection to your Neon database.
Testing Our Setup
Let’s test how this works. We won’t bore you with the details. If you want them, the code is in this repo:
https://github.com/argotdev/neon-lambda
We will run two load tests that simulate multiple users making concurrent requests to different endpoints. Test 1 will do this using a pooled connection to Neon, while test 2 will do this using a regular connection to Neon.
Here are the results for test 1:
node load-testing.js
Starting load test with 50 users for 300 seconds
Load Test Results:
==================
Total Requests: 7799
Successful Requests: 7799
Failed Requests: 0
Success Rate: 100.00%
Average Response Time: 175.62msHere are the results for test 2:
node load-testing.js
Starting load test with 50 users for 300 seconds
Load Test Results:
==================
Total Requests: 7858
Successful Requests: 7696
Failed Requests: 162
Success Rate: 97.94%
Average Response Time: 192.05ms
Error Distribution:
API Error: 500 - Internal Server Error
Endpoint: /sales
Response: {"message":"Internal Server Error"}: 43 occurrences
API Error: 500 - Internal Server Error
Endpoint: /users
Response: {"message":"Internal Server Error"}: 18 occurrences
API Error: 500 - Internal Server Error
Endpoint: /inventory
Response: {"message":"Internal Server Error"}: 69 occurrences
API Error: 500 - Internal Server Error
Endpoint: /fulfillment/1
Response: {"message":"Internal Server Error"}: 26 occurrences
API Error: 500 - Internal Server Error
Endpoint: /fulfillment
Response: {"message":"Internal Server Error"}: 6 occurrencesAs we can see, the pooled connection outperformed the regular connection. The regular connection was still OK (and with good error catching, it would have probably worked properly), but not the 100% pass of the pooled connection.
We can see why in our Neon dashboard:
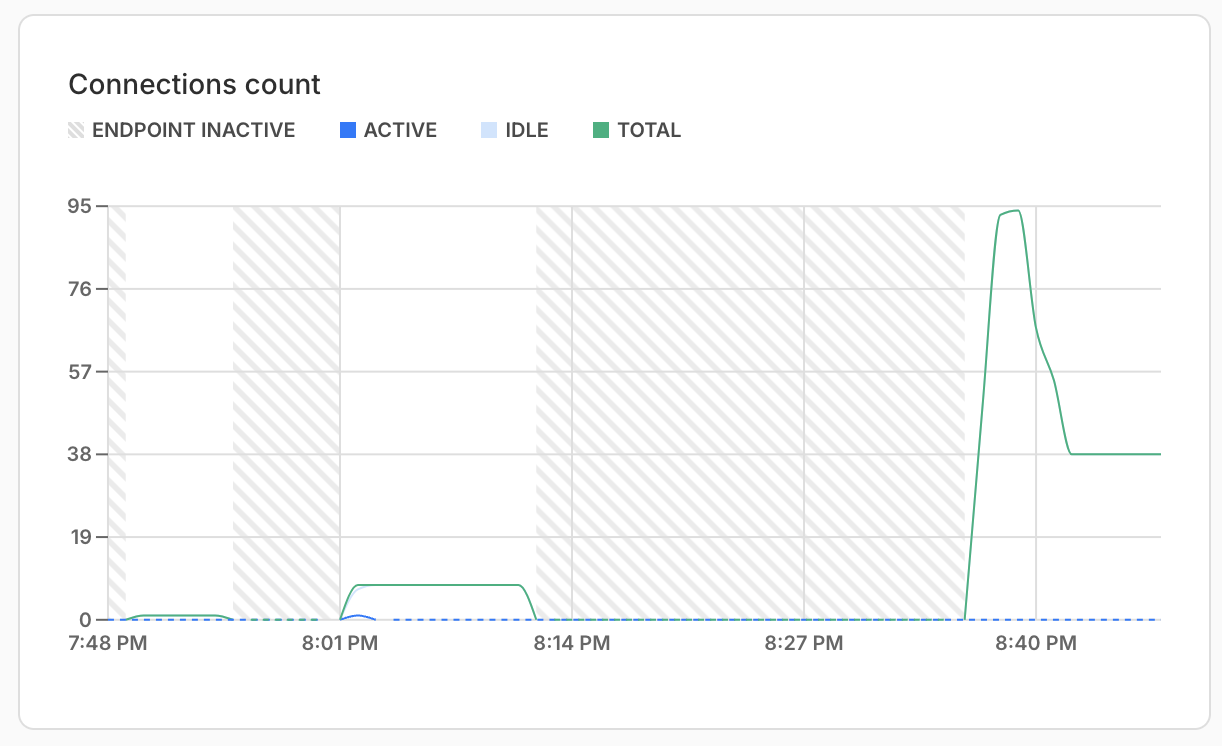
That first connection set is from test 1 with the pooled connection. Those 7,799 requests used just eight connections in total. The second spike is from test 2, which hit a max of 93 total connections. Now you can see why some might have failed and why pooled connections are vital when you have any load on serverless functions with Lambda. Imagine what happens when you have thousands of requests, like with Invenco!
There is a bonus here to using Neon. Here’s what happened when the connections started to rise during that second test:
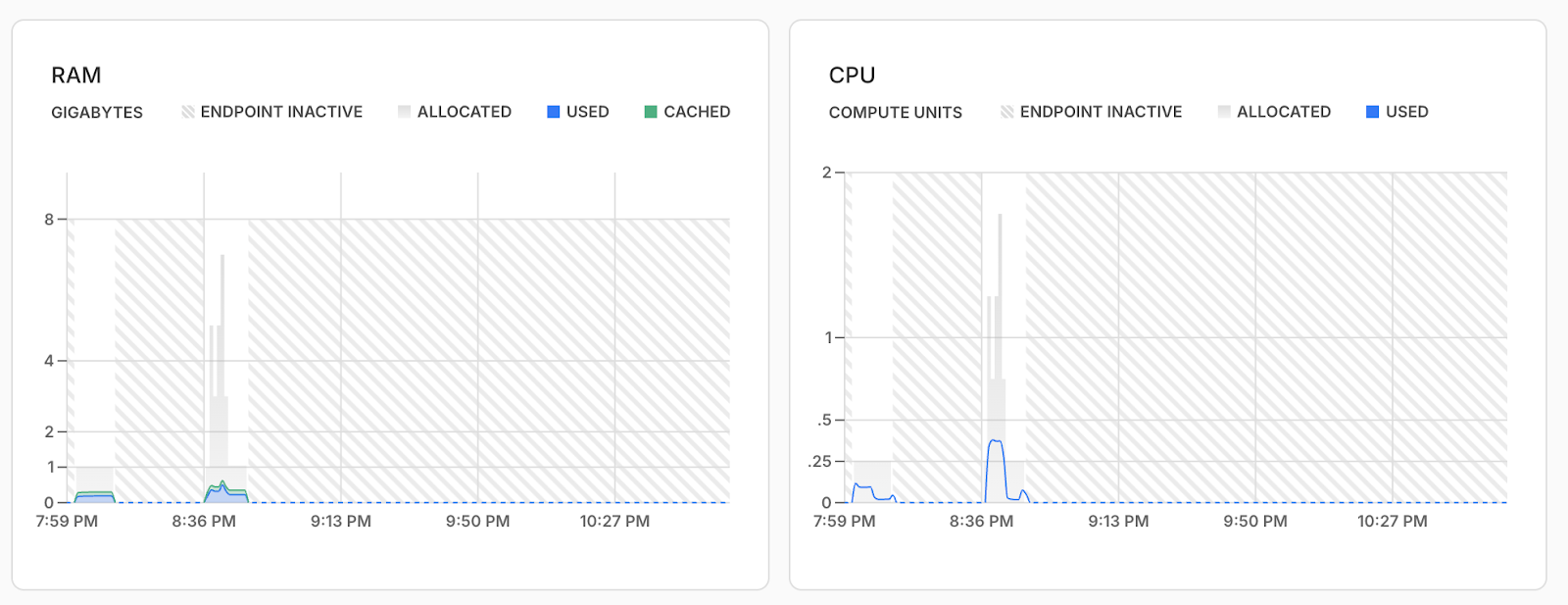
You can see that once Neon detected more usage for both memory and compute, it autoscaled the available resources to match. This is why, with better error logic, we’d probably have seen closer to 100% success on the second test, even with more connections, as we’d have retried the API calls and found more resources available.
Rethinking Database Scaling for Serverless Applications
We’ve seen here that connection management isn’t just a technical detail—it’s a fundamental architectural concern when building serverless applications. The traditional approach of “one Lambda, one connection” breaks down at scale, and even AWS’s solutions, like RDS Proxy, introduce complexity without fully solving the problem.
Neon’s approach stands out for two key reasons:
- It makes connection pooling a first-class citizen. Adding “-pooler” to your connection string is all it takes—no additional services, no complex configuration.
- The autoscaling capabilities work in concert with the connection pooling. Neon responded by scaling up resources rather than just failing connections when our non-pooled test hit limits.
This matters for teams building serverless applications. It means you can focus on building features rather than wrestling with infrastructure. The future of serverless isn’t just about scaling compute—it’s about all parts of your stack working together when that scaling happens.
Neon has a Free Plan. Create an account here and try it yourself (no credit card required).


