
Neon’s serverless architecture with decoupled storage and compute makes it possible to offer database branching via copy-on-write. This feature is among the most loved by teams using Neon, but if you’ve never seen it in action, it’s hard to visualize how it works or why it’s useful.
That’s why we’ve built this demo:
https://fyi.neon.tech/branching
Completing it takes less than 1 minute, but you will:
- Copy a 1TB Postgres database
- Alter some records
- Revert the database to the original state
Neon branches are what make this speed possible. Let’s take a closer look.
Copy-on-write in action
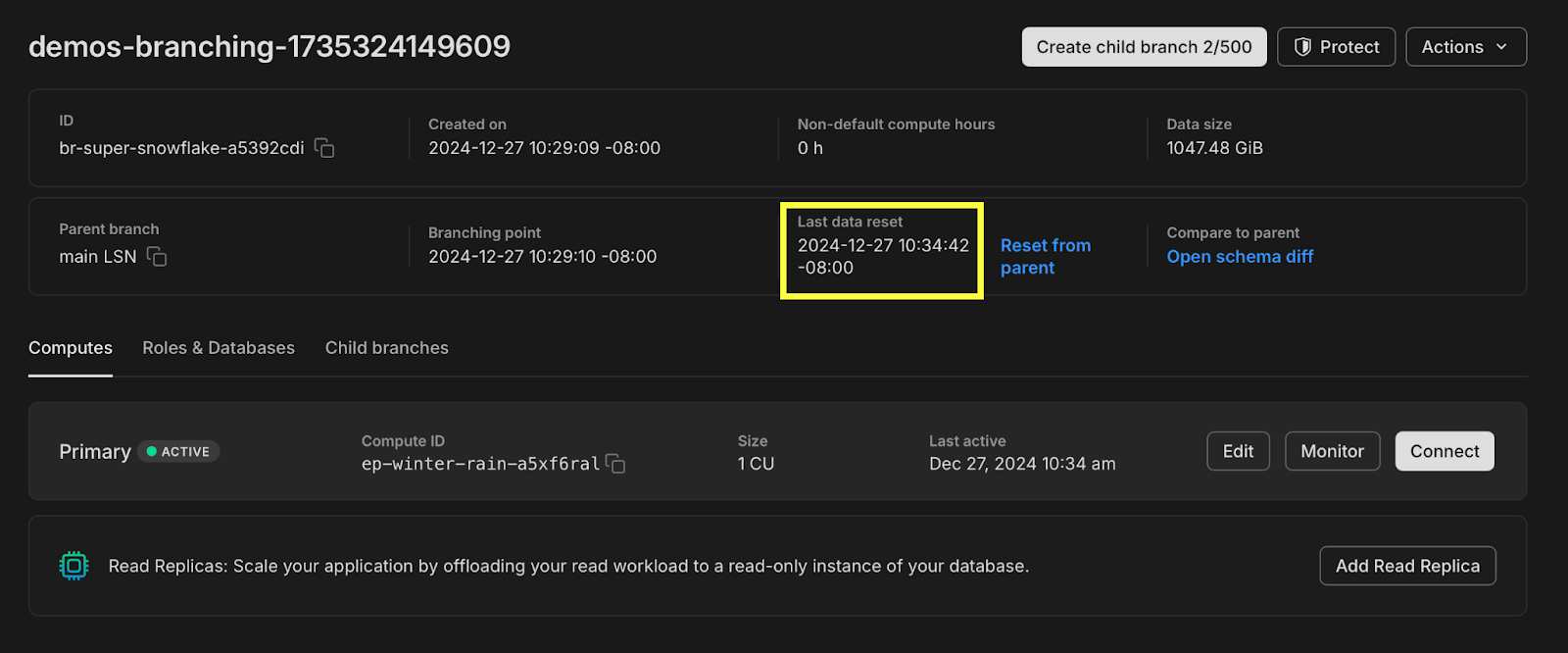
This demo lives within a Neon project. When we built it, we loaded the original 1 TB dataset (1047.48 GB to be exact) into the main branch of this project:
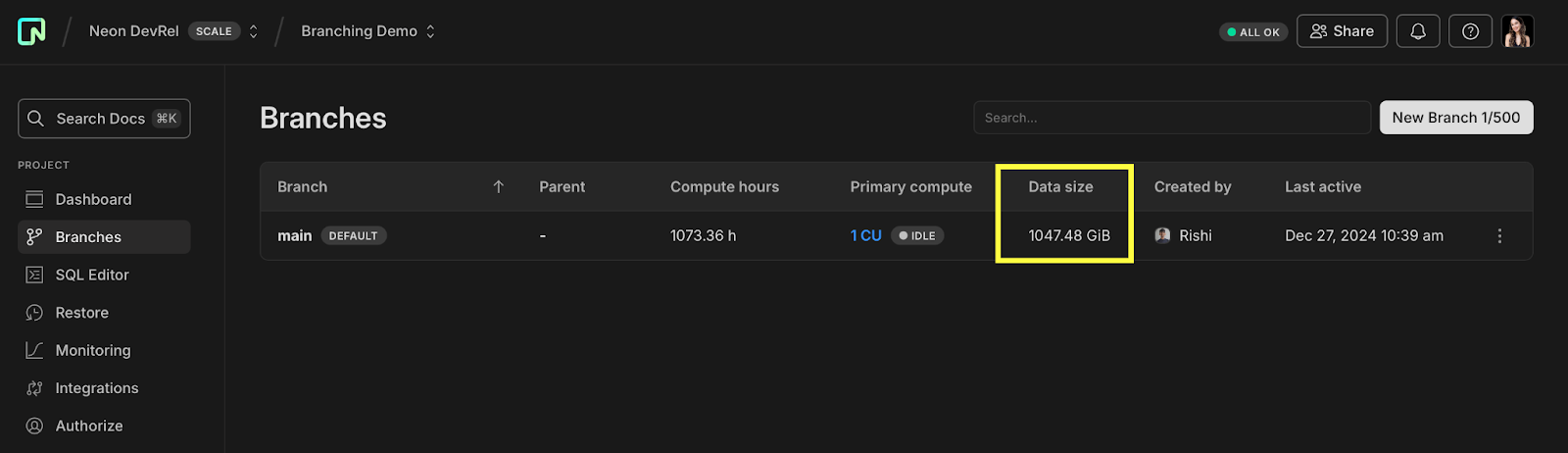
We used pg_dump/restore, which meant it took a while to load this dataset initially. If we had to do this every time a user created a copy, it would make for a very poor demo…
So, how do we manage to provide a unique database copy instantaneously every time a user follows the demo? It’s because all other “copies” that users create are child branches derived from this main branch.
When you click Copy in the demo, you’re actually creating a Neon branch under the hood:
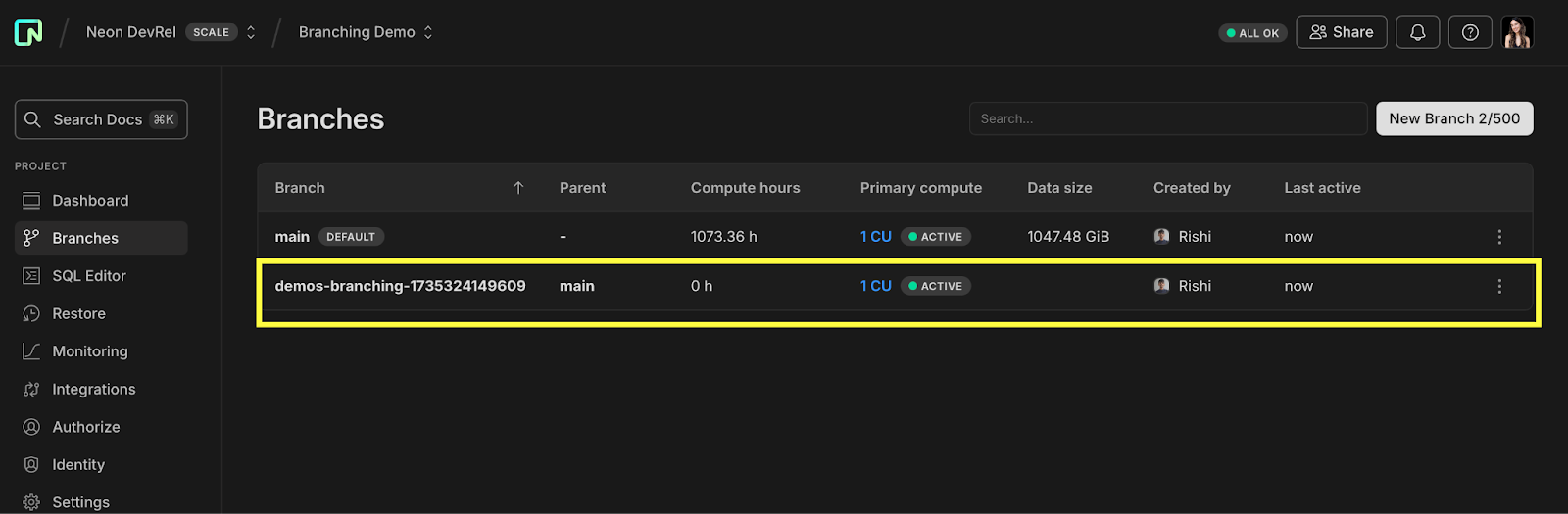
Thanks to the magic of copy-on-write, Neon branches are incredibly agile and can be treated as ephemeral. When you create a branch, Neon doesn’t have to load the entire dataset again. Instead, it references the same data pages as the parent environment (read about Neon’s storage design).
Since branches are ready instantly, even for very large datasets (in fact, the size of the dataset has no impact at all) they can be created for a specific purpose—a development task, a test run, a Vercel preview, this demo—and deleted once the task is done.
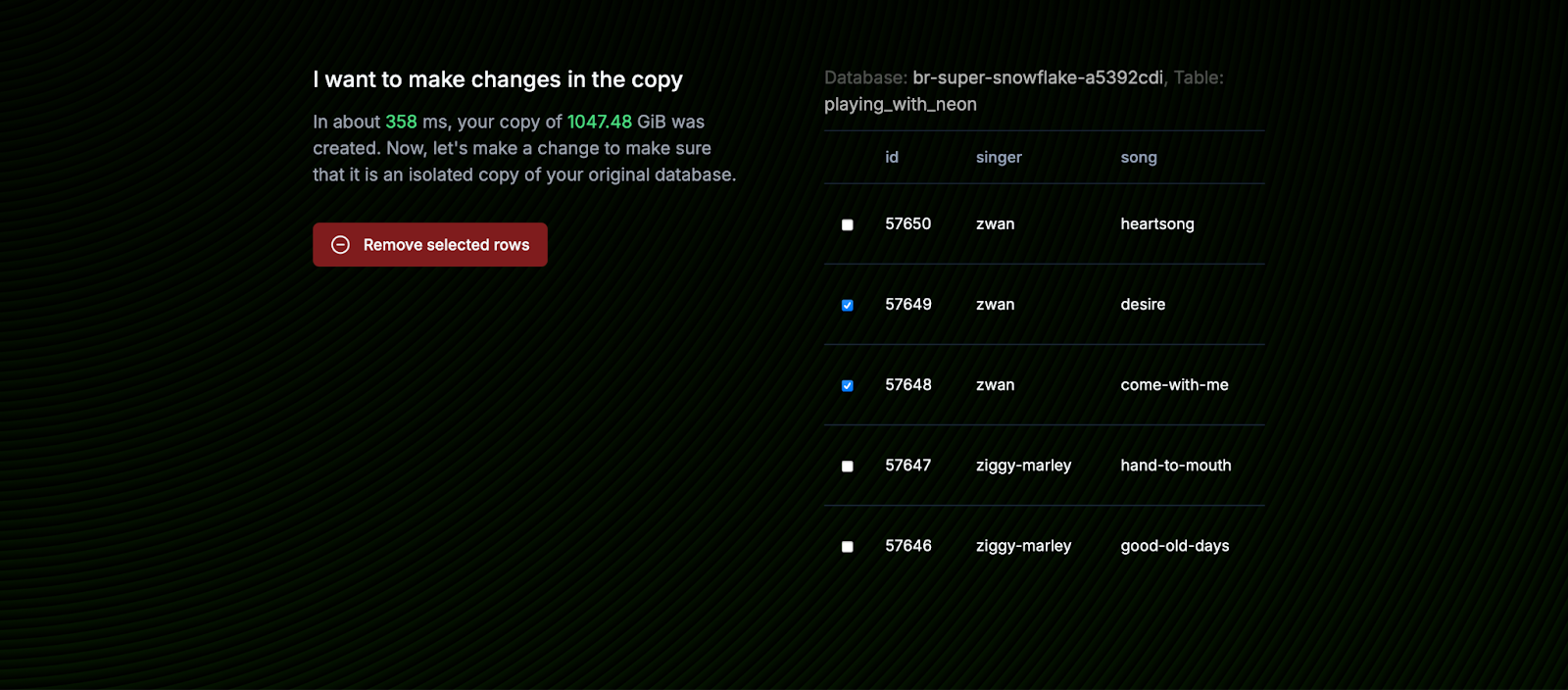
At the same time, they are completely isolated from their parent. When you start modifying records on them, Neon begins writing new pages for the changed data, which is what we were demonstrating here:
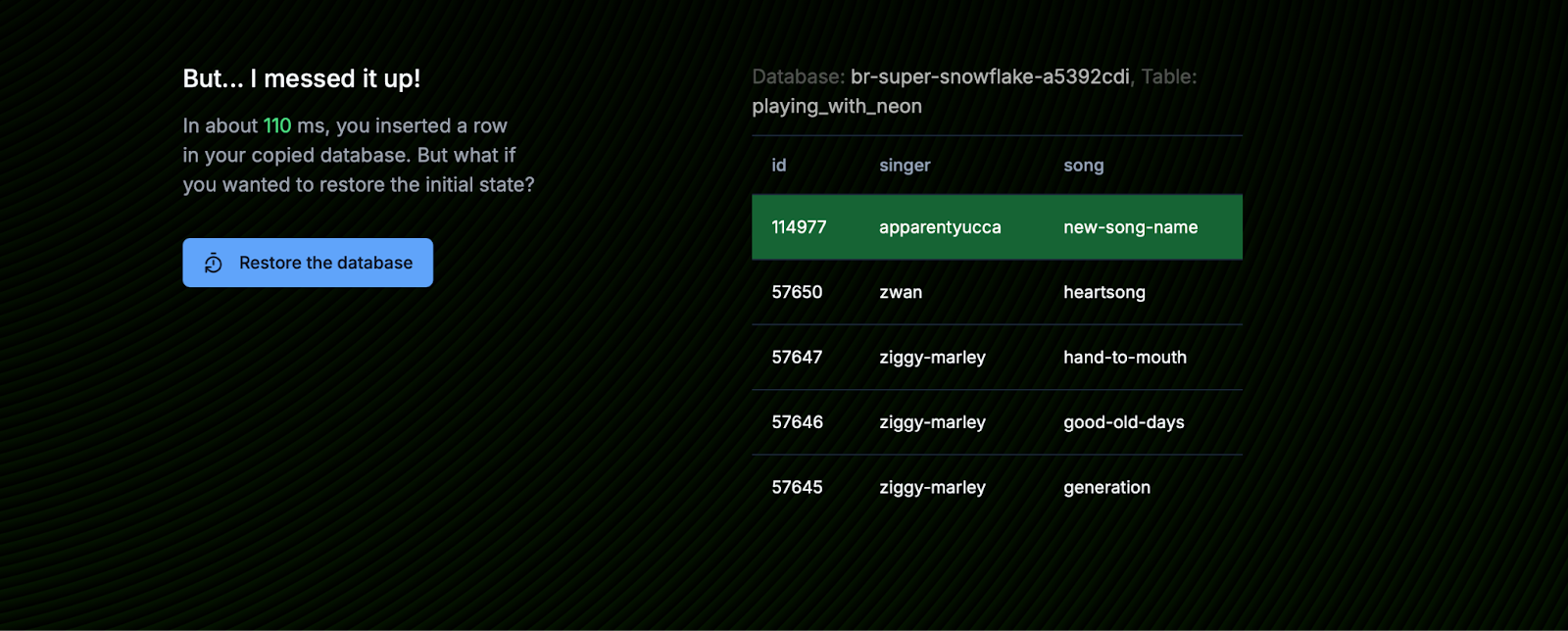
Copy-on-write also enables Neon to do some very cool things. For example, branches can be reset to match the parent environment instantaneously. This is what you experience during the demo, when you accidentally modify something and then revert it with just one click:
From demo to use case
You may still be thinking, this is flashy for a demo—but how can I benefit from it? As we said at the start of this post, branching is probably the most loved Neon feature by our users:
“We’re a small team, but we’re scaling quickly and doing a lot. We’re shipping multiple times a day—to do that, we need to test stuff quickly and merge to main very quickly as well. Neon branches are a game changer for this” (Avi Romanoff, Founder at Magic Circle – Read more)
“Branching saves us both money and developer time. We no longer have to set up an actual testing database instance and make sure the data is always synced with production. We now spin up an ephemeral branch when we need to and then tear it down via the create/delete Github Actions” (Angelina Quach, Software Engineer at Shepherd – Read more)
“Database branching is the best quality-of-life improvement to my tech stack that I can think of in recent years. Second to maybe only Copilot” (Miguel Hernandez, Backend Tech Lead at Neo.Tax – Read more)
Once you’ve experimented with branches and understand the basics of how they work, it gets easier to appreciate their potential. Here are the most popular use cases among our user base:
- Ephemeral dev/test environments. If you sync a testing dataset into a Neon main branch, you can use branches to create as many ephemeral environments as you need for development and testing. Each branch serves as a clean, independent workspace. When it’s time to resync the environments, you do it with a single click or an API call. Read more.
- Previews. You can also use Neon branches to automatically create a preview environment for each pull request, e.g. via Vercel. Each preview branch mirrors the same state as production at the time it was created. When the pull request is closed, you delete the branch. This guide explains how to set this up with Vercel.
- Local development. On a team, every engineer can have their own Neon branch as a personal development environment, preloaded with a realistic dataset.
Not all branching is the same
Neon is not the only database that offers a “branching” feature, but not all branches are created equal. We like to distinguish between three types of branching:
Schema-only branching
Schema-only branching means you start with your original database, and when you branch it, you clone only the schema or table structure and definitions. You do not include the data in the branch.
For example, if we had to create this database:
create table users (
id int generated always as identity primary key,
username text not null,
created_at timestamptz not null default current_timestamp
);
insert into users (username) values ('bryan'), ('anna'), ('brian');With this information:
-- parent database
select * from users;
id | username | created_at
----+----------+-------------------------------
1 | bryan | 2024-09-24 23:37:23.282508+00
2 | anna | 2024-09-24 23:37:23.282508+00
3 | brian | 2024-09-24 23:37:23.282508+00After branching it with a schema-only implementation, it would show this:
-- schema-only branched system
select * from users;
id | username | created_at
----+----------+------------
(0 rows)Only the table definitions exist, but the data has not been brought into the branch with it. This is the implementation of branching that Supabase and Planetscale offer (Planetscale has a separate Data Branching feature that we’ll discuss in a minute).
Branching schemas can be useful for some very specific use cases (which is why we’re planning to offer this in Neon soon) but for most workflows, schema-only branching has a massive trade-off: it still requires loading a dataset into every branch. If you wanted to implement this type of branching for your dev/test environments for example, you would still be stuck managing seed data files, which is complex (code to manage), slow (generation takes time), and error-prone (not necessarily representative of production).
Schema and data branching
In a schema and data branching system, when you branch the database in our example, you would be left with exactly the same thing:
-- parent database
select * from users;
id | username | created_at
----+----------+-------------------------------
1 | bryan | 2024-09-24 23:37:23.282508+00
2 | anna | 2024-09-24 23:37:23.282508+00
3 | brian | 2024-09-24 23:37:23.282508+00-- schema + data branched system
select * from users;
id | username | created_at
----+----------+-------------------------------
1 | bryan | 2024-09-24 23:37:23.282508+00
2 | anna | 2024-09-24 23:37:23.282508+00
3 | brian | 2024-09-24 23:37:23.282508+00In this model, all the table definitions, indexes, and data are available in your branch. This is what Neon offers, together with Planescale’s Data Branching feature.
But in the case of Planetscale, branching with schema and data involves loading data from the latest backup available. This means that if we had to build our 1TB branching demo using Planetscale’s Data Branching, we would have to wait for the 1 TB dataset to be restored from backup every time a user creates a branch, which most certainly wouldn’t make for a 1 s experience.
It’s easy to see how the Planetscale method is also problematic at scale, e.g. when many environments have to be created programmatically from branches.
The next frontier: Schema and data branching w/ PII transformed
From here, it’s easy to see what the next step would be. If we consider Neon’s model for ephemeral environments, if you have PII and can’t use production data directly for dev and testing, you still have to manually load your transformed dataset at least once to the main branch (and keep it updated). Many environments can be directly derived from it, but some management of seed/transformed data is still necessary.
Instead, the ideal workflow would be
- Branch directly from production,
- Get only a representative subset of data (vs the whole database),
- Have PII, emails, and other sensitive information already transformed
Something like this:
-- parent database
select * from users;
id | username | created_at
----+----------+-------------------------------
1 | bryan | 2024-09-24 23:37:23.282508+00
2 | anna | 2024-09-24 23:37:23.282508+00
3 | brian | 2024-09-24 23:37:23.282508+00-- schema + data branched system
select * from users;
id | username | created_at
----+----------+-------------------------------
1 | NOT BRYAN | 2024-09-24 23:37:23.282508+00
4 | AI OF ANNA | 2024-09-24 23:37:23.282508+00In this hypothetical subset,
- id’s 2 and 3 had been removed
- id = 1 has been transformed using the function uppercase(prefix(’not ’, username))
- id = 4 has been generated to create new data needed for this environment
This is a feature we’re actively working on at Neon. It’s still early days, but if you’re interested in trying out our MVPs and providing feedback while we build it, reach out to us via Discord or this form.
In the meantime, start branching
You can sign up for the Neon Free Plan and build your first branching workflow right away. You don’t need a credit card, and you get 10 branches per project for free. Once you’re ready to upgrade to a paid plan, you’ll get 500 branches per project, with this limit increasing very soon to thousands of branches.
If you have any questions, ask us on Discord!

