
Previously in this series, we discussed implementing database-per-user architecture in Neon with a shared application environment communicating with individual user databases.
That approach keeps operational complexity contained by minimizing the number of software systems deployed and limiting the flexibility you can offer your customers. But the world is a complex place, and sometimes your customers need more than the “one size fits all” service approach allows.
Isolated application environments are exactly what they sound like. It’s not just databases which are separated from each other in this mode: you’re deploying and managing a copy of the entire system for each customer.
Why Even Consider Isolated Environments?
This is not multitenancy by any stretch of the definition, although a well-equipped control plane can let you manage customer deployments almost like it is. First, though, why go back to this seemingly archaic way of doing things?
Let’s say upfront that this is not a path to embark upon lightly. Shared resources allow economization on scale that you just don’t get with a deployment per customer; there has to be a very good reason, or two, for adopting this approach.
First, there are geographical and political requirements. Depending on the type of data your customers store, governments may regulate where you’re allowed to store it through data sovereignty or data residency laws. Customers who operate in specific regions can also simply want their systems to be close by; computers and networks may have gotten faster over the decades, but Hopper’s nanoseconds are still as long as they ever were.
Second, there’s the ability for customers to dictate the pace of upgrades. Some customers — in particular, older, bigger customer organizations in more institutional sectors — may expect to control this in order to minimize and manage disruptions to their own end users’ work. This isn’t possible in a shared environment, since the pace of application development dictates the only allowed version of the database schema.
There is another reason, which is that you intend to tailor the application, and/or the database, to individual customers. This is not a good reason: bespoke customizations, especially in the schema, effectively make each deployment a separate software product. Instead of maintaining a single product line and stamping out instance after identical instance, you take on responsibility for adapting bugfixes and upgrades to each and every variation. We’ll talk about how to handle the inevitable one-off requests in the next section.
Designing for Isolated Environments
Isolated environments shouldn’t be confused with on-premises deployments. You’re still the service provider and manage the infrastructure, including the Neon project that underpins each instance. This includes networking too: it’s up to you to determine how a given customer user connects to their instance. You could set each customer up with a subdomain, which wildcard certificates make particularly easy, but can also get more exotic with “bring your own URL” options.
Unlike the shared environment strategy, there isn’t much to do internal to the system being deployed! There’s no need to identify a user with their customer organization in your catalog database, no need to route queries and mutations to the appropriate database. This strategy pushes complexity into provisioning and deployment. You build the software itself like it’s a single-tenant system — mostly.
Because each deployment serves a single tenant, there’s more of a temptation (and it’s more possible) to customize. This, again, is your worst enemy. Instead, you should take care to think of opinions and requests for bespoke work as indicating customer needs and wants that point a possible direction to the future of the whole product. Channel them into your standard requirement evaluation, design, and development processes rather than doing unreproducible one-off work.
Capacity limits and enabled features are always constant within each deployment. This means there’s less call for feature flag management compared to a shared system, but it’s important to keep the source of truth for enablement in the catalog database. This allows you to validate and compare these settings in one place. However, it doesn’t mean that customer applications should all check in with the catalog database whenever they need to verify a feature setting! Instead, settings should be forwarded to the application database when configured in order to minimize roundtrip time for user requests.
Managing Isolated Environments
Like any other database-per-user system, isolated environments need to be provisioned, monitored, and maintained. Also like other such systems, this is all best done from a central control plane and catalog database. Even if a problem for one user stands no chance of being a problem for others as happens in shared application environments, those isolated problems are still hard to investigate and remediate if you don’t know how to find them.
The main distinguishing factor for control planes in an isolated-environment setting is the complexity of provisioning. A new customer needs not just a Neon project, but a whole new application deployment with its attendant delivery pipeline, network configuration (some of which may require customer input, for example requesting a TLS certificate for a custom URL), and observability infrastructure. Automation is very much a journey in this kind of system, and the pace will be determined by the frequency with which you onboard new customers. If your customers are fewer and larger, it’s possible to get by for longer on engineering documentation and active account management.
Next to onboarding and feature enablement, it’s also crucial to surface deployed versions in the control plane. As your application and your tools for managing it continue to mature, the control plane will be where you go to roll out upgrades.
Software Development Lifecycles and Isolated Environments
Independent versioning per customer is one of the main reasons to take an isolated-environments approach, but using it effectively requires strict discipline in your development lifecycle. Versioning is never wholly linear, even if there’s a “main line” of major version releases; each major release has a lifecycle of its own, with minor versions fixing bugs and making more modest improvements. Development effort too is usually divided between work toward the next major release and updates to already-released versions.
The figure below shows three views of a series of software releases. The first release, 1.0.0, receives ongoing support in the form of patches and feature releases while work continues on version 2. After 2.0.0 is released, a bug is discovered and patches are backported to the 1.1.x and 1.2.x series’ database schemata:
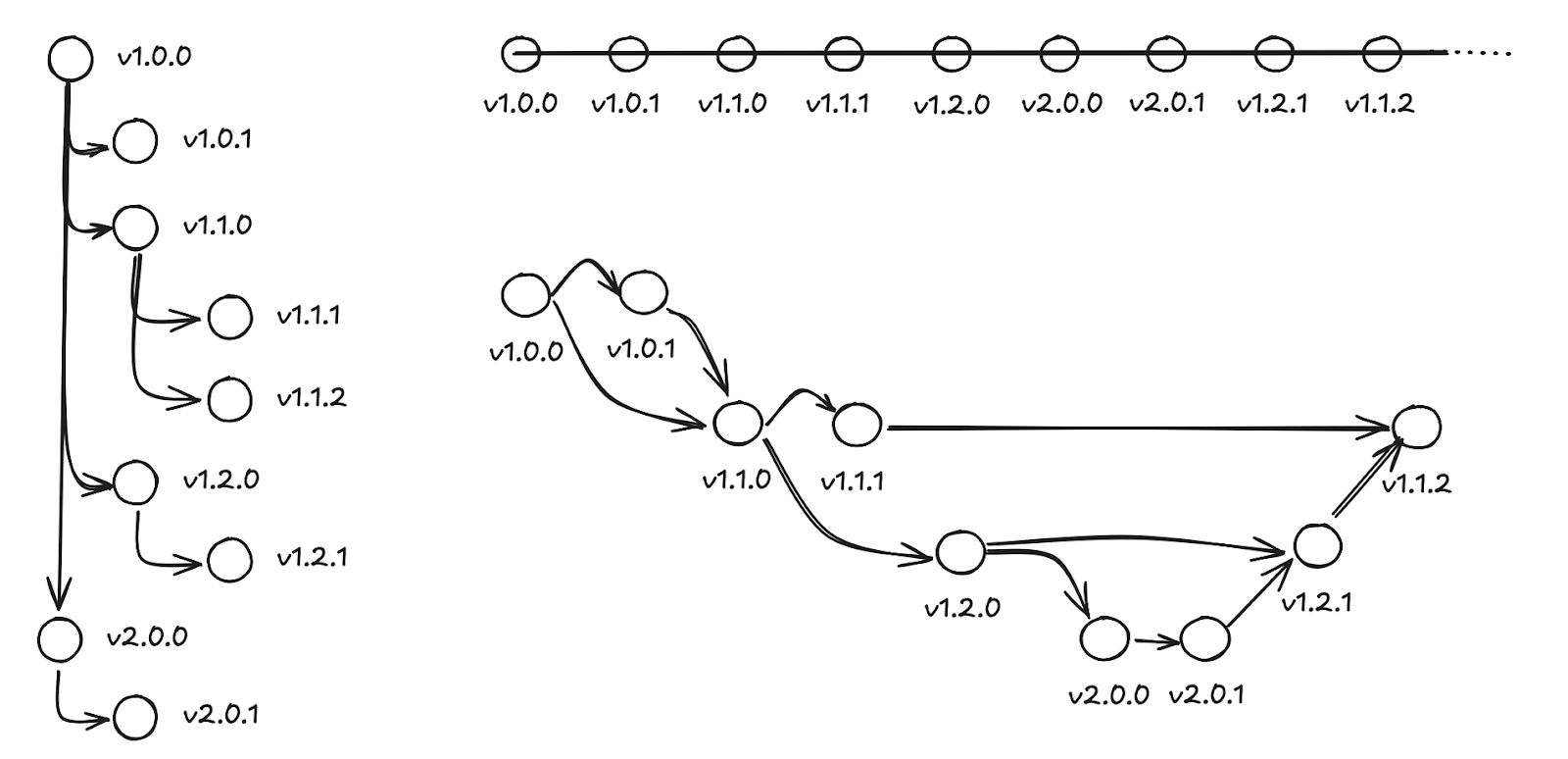
The first view, on the left, shows the release lineage in a SemVer-style major/minor/patch hierarchy. The second, at top right, shows the actual order in which each version arrived.
Finally, the third view shows the flow of schema changes between versions, which is much more complicated! There’s a “main line” from 1.0.0 through 1.1.0 and 1.2.0 to 2.0.0, but even patch releases may or may not inform the schemata of subsequent versions. Here, for example, the fix in 1.0.1 is also included in 1.1.0 to forestall the same bug happening in that series, but the fix in 1.1.1 only affects the 1.1.x series – changes in 1.2.0 have rendered it moot in later versions.
This isn’t just complicated to manage, it also poses extra difficulty when customers do want to upgrade to the next release. Because changes and fixes from “later” in the version hierarchy can get backported to “earlier” release series, it’s important to linearize upgrades to keep the number of possible upgrade paths to a minimum. The path from 1.0.1 to 1.2.0 goes through the 1.1.x series, in other words. Even though, for example, 1.2.1 contains the same schema change as 1.1.2, the upgrade process as a whole is much more reliable if an older schema gets it from 1.1.2.
Idempotent upgrades are a very effective tool in this situation. If the same columns must all be added in 2.0.1 and the backport releases 1.2.1 and 1.1.2, the higher-versioned scripts can check for their presence, types, and constraints before modifying the schema. This prevents conflicts and migration failures when a deployment that received the 1.1.2 patch goes through later upgrades.
It takes a lot of effort to manage versions in a scenario where individual systems can be at any version at any time. But overall, it’s much easier for you to maintain a few well-defined upgrade routines that migrate from the latest patch on one major-minor lineage to the next .0 or .0.0 release and resume the main-line sequence of schema changes from there than it is to deliver point-to-point upgrades from any version to any greater version.
Conclusion
Isolated environments are an investment. They offer your customers flexibility in geographic location, version management, and more — but that flexibility in turn adds substantially to your operational overhead. Still, for the right circumstances, there’s no substitute.
This article is part of a series. Check out the previous three articles on the topic of building database-per-user architectures:

