
A common SaaS pattern involves deploying a single application environment shared among all users. However, RAG presents additional reliability and security challenges, relying heavily on user-provided information and unpredictable model APIs. This article covers a multi-tenant RAG pipeline example (available on GitHub) that leverages Neon’s database-per-user design and the multi-tenancy features of the Inngest workflow engine.
The Noisy Neighbor Problem: RAG Edition
The Noisy neighbor problem can be described as:
“where a few customers make up a disproportionate fraction of the system’s overall activity, and other customers suffer higher latencies, locks, and unavailabilities.”
As RAG applications heavily rely on data input, vector database, and external API calls (models and tools), the Noisy neighbor problem can come up at two levels:
- At the database level, an organization’s usage or amount of data can impact the overall performance of the application
- At the RAG execution level, a spike in usage can lead to capacity issues (e.g., rate limits), slowing down or blocking other organizations’ RAG executions.
Adds to the Noisy neighbor problem the cost and data security considerations:
- One organization’s usage should not lead to an unwanted surge in LLM cost
- One organization should not be able to access another organization’s data (database or vector)
This is where the concept of multi-tenancy, which consists of isolating the data of each organization and applying guaranteed capacity, comes into play:
- Each organization should only get access to their contacts
- One organization’s usage of the RAG pipeline should not impact the capacity of others
Our example application is a CRM that enables users from different organizations to upload contact CSV files, which get enriched and embedded into a vector store, which is later used for semantic search:
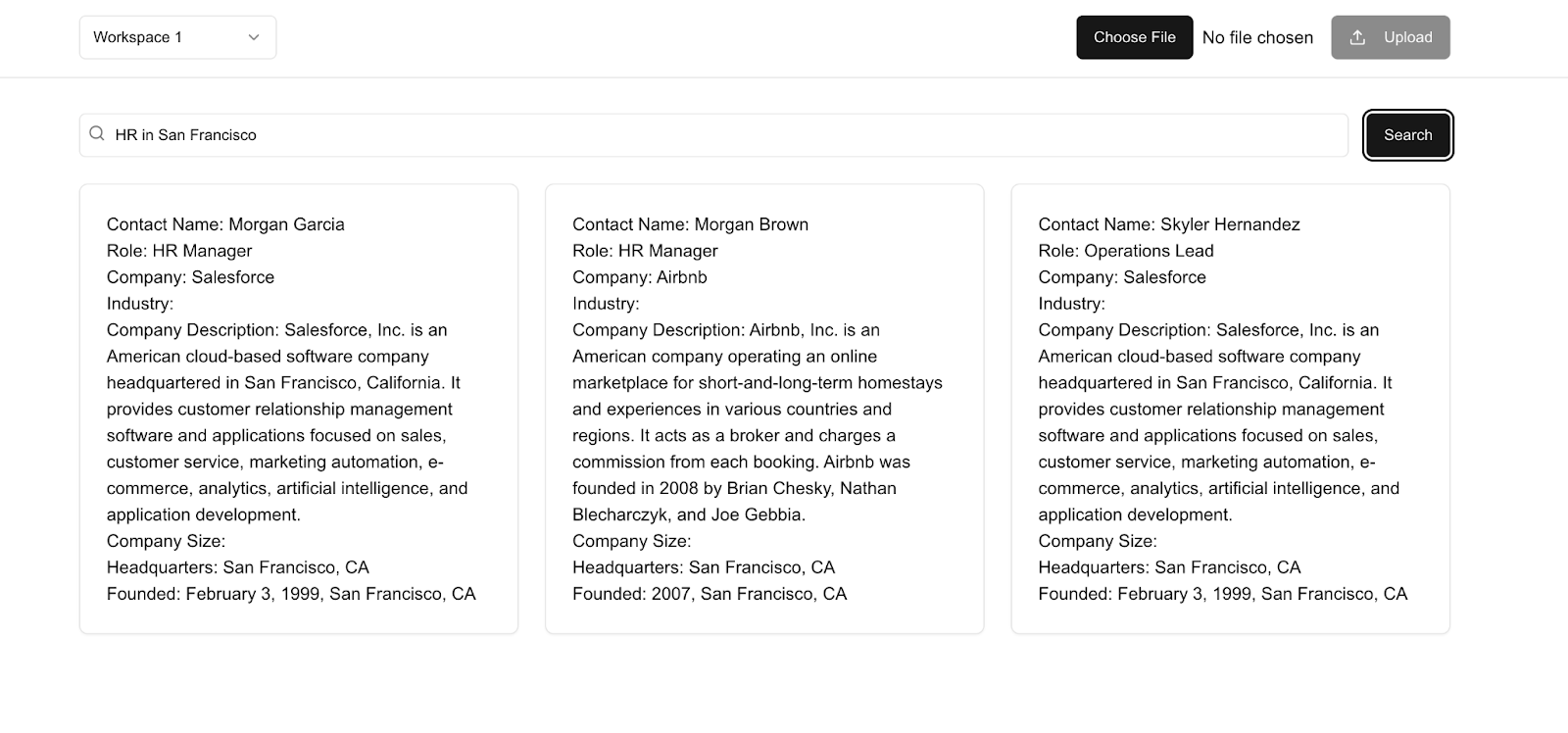
Each organization gets assigned a dedicated application and vector Neon database and benefits from guaranteed capacity by leveraging Inngest workflows:

Let’s walk through its implementation.
Data Isolation: Dedicated Neon Projects Per Tenant
Let’s first look at how our application isolates each workspace’s application and vector data into dedicated databases.
Database architecture
To provide complete data isolation and guaranteed database performance, our application leverages Neon’s “database-per-user” design, where each organization gets a new Neon project containing a contacts and embeddings tables:

For the sake of simplicity, our demo application exposes a /api/setup endpoint that creates two workspaces to test the application using the Neon API.
import { neon } from "@neondatabase/serverless";
import { neonApiClient, getTenantConnectionString } from "@/lib/neon-tenant";
import { setupTenantSchema } from "@/lib/neon-tenant/setup";
const NUMBER_OF_WORKSPACES = 2
async function seed() {
async function createProject() {
const { data } = await neonApiClient.POST("/projects", {
body: {
project: {},
},
});
return data?.project.id;
}
const tenantPromises = [...Array(NUMBER_OF_WORKSPACES)].map(async () => {
const projectId = await createProject();
const uri = await getTenantConnectionString(projectId!);
const tenantClient = neon(uri!);
await setupTenantSchema(tenantClient);
return projectId;
});
const globalClient = neon(process.env.POSTGRES_URL as string);
const projectIds = await Promise.all(tenantPromises);
for (let i = 0; i < projectIds.length; i++) {
await globalClient(
`INSERT INTO workspaces (name, project_id) VALUES ($1, $2)`,
[`Workspace ${i + 1}`, projectIds[i]]
);
}
}In a real-world application, each workspace creation sets up the Neon project and creates the schema, as covered in the db-per-tenant repository. Creating a new workspace and its associated databases only takes a few seconds and can be easily integrated into a Next.js API route.
Note that Neon’s database-per-user design differs from regular isolated database architecture. By leveraging Neon projects, our end-users benefit from complete data isolation without the usual associated cost of duplicated architecture.
Querying multi-tenant databases
Neon’s serverless SDK makes connecting to a database on the fly easy. Our project provides a getTenantConnectionString(workspaceId) helper that retrieves the Neon project associated with a given workspace:
import { neon } from "@neondatabase/serverless";
import { neonApiClient } from "@/lib/neon-tenant";
export async function getTenantConnectionString(workspaceId: string) {
// connect to the application's shared database
const sql = neon(process.env.POSTGRES_URL as string);
// this could be cached using Vercel KV
const records: any = await sql(
`SELECT project_id FROM workspaces WHERE id = ${workspaceId}`
);
if (records && records[0] && records[0]["project_id"]) {
const { data } = await neonApiClient.GET(
"/projects/{project_id}/connection_uri",
{
params: {
path: {
project_id: records[0]["project_id"],
},
query: {
role_name: "neondb_owner",
database_name: "neondb",
},
},
}
);
return data?.uri;
} else {
throw new Error("Unable to load tenant");
}
}This helper is used to connect to each workspace application and vector database dynamically:
// connecting to the workspace's application database
const uri = await getTenantConnectionString(event.data.workspaceId);
const sql = neon(uri!);
// connecting to the workspace's vector database
const vectorStore = await loadVectorStore(workspaceId);
const results = await vectorStore.similaritySearchWithScore(query, 3);By leveraging getTenantConnectionString(), our RAG now benefits from guaranteed database performance and data isolation for each workspace.
Let’s now see how our RAG guarantees fair processing performance by applying throttling and concurrency per workspace.
Noisy neighbor prevention: Guaranteed RAG workflow capacity
Our RAG relies on two rate-limited and costly 3rd party APIs: the SERP and OpenAI APIs.
To protect our RAG from spikes in usage that could affect the application’s performance and cost, our RAG is implemented leveraging Inngest workflows and its multi-tenancy features.
Our first AI workflow performs enrichment (using the SERP and OpenAI APIs) and generates an embedding document for each contact of the CSV file:
"use server";
import csv from "csvtojson";
import { inngest } from "@/inngest/client";
// Transform the CSV file into an array and trigger the enrichment workflow for each contact
export async function uploadFile(formData: FormData) {
const workspaceId = formData.get("workspaceId") as string;
const file = formData.get("file") as File;
const contactsFileContent = await file.text();
const contacts = await csv().fromString(contactsFileContent);
await inngest.send(
contacts.map((contact) => ({
name: "contacts/enrich",
data: {
contact,
workspaceId,
},
}))
);
}The contact enrichment workflow ensures a guaranteed capacity with a workflow-level throttling configuration using the event.data.workflowId:
import { inngest } from "@/inngest/client";
export const enrichContactWorkflow = inngest.createFunction(
{
id: "enrich-contact",
// The workflow is throttled to 10 concurrent executions every 10 seconds per workspace
throttle: {
limit: 10,
period: "10s",
// The throttling is applied per workspace to ensure guaranteed capacity
key: "event.data.workspaceId",
},
},
{ event: "contacts/enrich" },
async ({ event, step }) => {
// ...
}
);The throttling configuration assigns each workspace to its own capacity, matching the OpenAI and SERP rate limits:

The same principles are later used to insert the embeddings into the vector store in batches of 100 documents. By using the event.data.workspaceId, each batch is guaranteed to contain documents from the same workspace:
import { inngest } from "@/inngest/client";
import loadVectorStore from "@/lib/vectorStore";
export const embedContactWorkflow = inngest.createFunction(
{
id: "embed-contact",
// The batch is throttled to 100 contacts every 60 seconds per workspace
batchEvents: {
maxSize: 100,
timeout: "60s",
// Contacts are grouped by workspace to be saved in the proper vector store
key: "event.data.workspaceId",
},
},
{ event: "contacts/embed" },
async ({ events, step }) => {
// we get the vector store dedicated to the workspace
const vectorStore = await loadVectorStore(events[0].data.workspaceId);
await step.run("embed-contacts", async () => {
await vectorStore.addDocuments(events.map((e) => e.data.document));
});
}
);We finally see our loadVectorStore(workspaceId) in action, which is used in combination with workspace-based batches.
Conclusion
This example is the perfect illustration of how putting a RAG into the users’ hands brings similar challenges as deploying SaaS applications:
- One customer spike in usage can affect the global application’s performance
- Any data leak between organizations can lead to a loss of trust
- RAGs rely on costly external services (ex, OpenAI) that should be pretty used by all users of the application
Fortunately, Neon’s database-per-user and Inngest’s throttling and batching per key features make it easy to isolate workspaces into their own data and RAG workflows without any additional infrastructure work or cost.
Feel free to explore this article’s demo by looking at the repository on Github, running it locally, or quickly deploying it on Vercel.
Neon is a serverless Postgres platform that helps you build faster. We have a generous Free Plan – create your account here (no credit card required). You can add the Inngest integration in one click.



